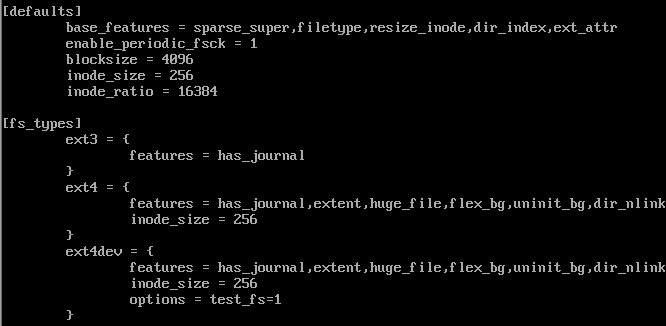
samba 서버 사용중 묘하게 버퍼 케시 메모리가 높게 나와서 의야해 했다. 처음엔 메모리가 부족해서 그런가? 싶어서 증설하였으나 똑같은 증상을 보였다. 여유 있는 메모리들이 얼마 없어서 메모리 증설을 하였으나 자원이 들어오는 족족 buff/cache 에 맵핑 되는걸 확인 할 수 있었다. 단순히 메모리의 문제인가 아니면 buff/cache 의 문제인가 잘 몰라서 알아보도록 하자. buff/cache는 뭘까? 일단 buff란 프로세스가 사용하는 메모리 영역이 아니고 시스템 성능향상을 위해 커널에서 사용하고 있는 영역! 이다 cache는 페이지 캐시라 불리는 캐시 영역에 있는 메모리 양을 위미한다 I/O관련 작업을 더 빠르게 진행 하기 위해 커널에서 사용하고 있는 영역이다. 자 그러면 사용자 확인을 해보자 ..